
Ansible Automation
Ansible is an open-source automation tool used for configuration management, application deployment, and IT orchestration. It is simple, agentless, and designed to simplify complex IT tasks.
Ansible is having 3 major tasks :
1. Installation
2.Configuration
3. Deployment
1. Installation : Installation involves setting up and provisioning software or services on managed nodes. This task ensures that required tools, packages, and dependencies are installed and ready for use across multiple systems.
Use Cases:
- Installing web servers like Apache or Nginx.
- Provisioning databases like MySQL, PostgreSQL, or MongoDB.
- Setting up programming environments (e.g., Python, Node.js, Java).
Example Of Playbook for installation :
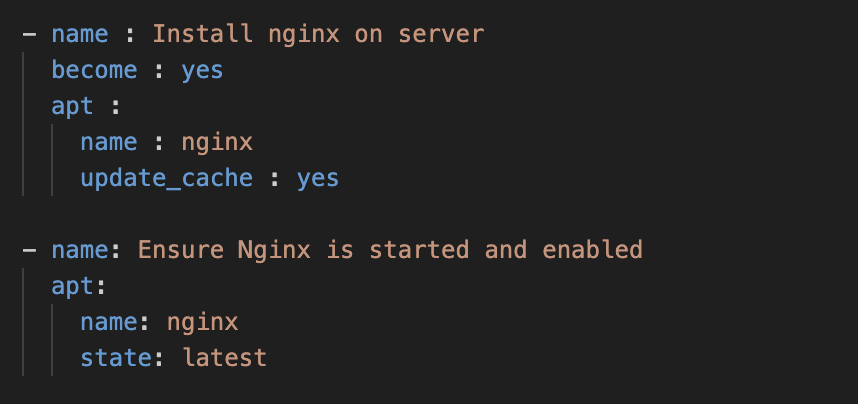
2. Configuration : Configuration involves setting up software and system parameters to ensure that systems meet specific requirements. Ansible manages configuration files, system settings, and environment variables to achieve desired states consistently.
Use Cases:
- Configuring a web server (e.g., setting up virtual hosts in Apache or Nginx).
- Managing system users, groups, and permissions.
- Applying security settings (e.g., firewall rules, SSH configurations).
Example Of Playbook for configuration :

3. Deployment : Deployment refers to automating the process of delivering applications, services, or code to production or staging environments. Ansible ensures that deployments are repeatable, consistent, and minimize downtime.
Use Cases:
- Deploying web applications (e.g., Node.js, Django, or React apps).
- Managing rolling updates for zero-downtime deployments.
- Deploying containerized applications using Docker or Kubernetes.
Example Of Playbook for configuration :
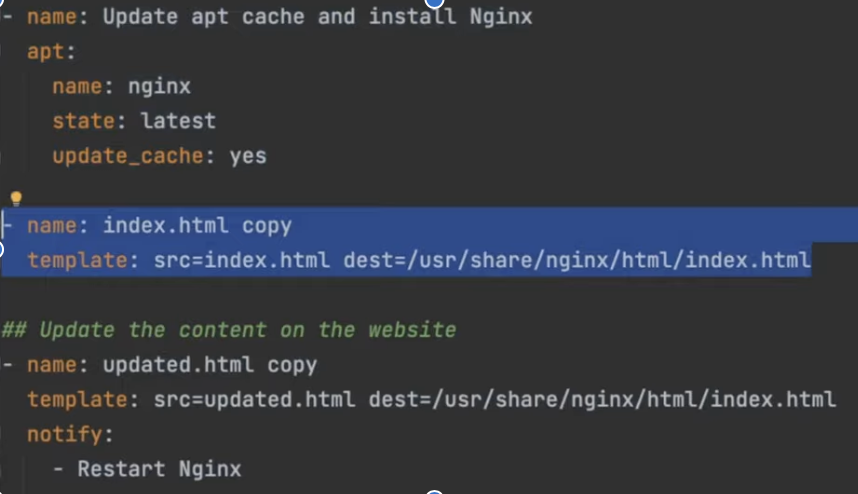
Why Should We Use Ansible Instead of Direct SSH Commands?
Let’s consider a simple scenario to illustrate why Ansible is a superior choice compared to manually executing commands over SSH. While SSH allows you to run commands on remote systems, Ansible enhances this process by introducing automation, scalability, and consistency.
Lets take a look at without ansible if you want to install a python library & apache2 then how you can install :
| Without Ansible | With Ansible(Using Playbook) |
| sudo apt-get updatesudo apt install -y python3sudo apt install -y apache2sudo systemctl start apache2sudo systemctl enable apache2 | – – – –name : Installing packages for python env become : yes apt : name : python3-pip update_cache : yes–name : Install apache2 become : yes apt : name : apache2 update_cache : yes |
For macOS
Step 1: Ensure Homebrew is Installed
Homebrew is a package manager for macOS. To check if it is installed, run:
brew –version
If Homebrew is not installed, use the following command to install it:
/bin/bash -c “$(curl -fsSL https://raw.githubusercontent.com/Homebrew/install/HEAD/install.sh)”
After installation, update Homebrew:
brew update
Step 2: Install Ansible
Install Ansible using Homebrew:
brew install ansible
Step 3: Verify the Installation
After the installation is complete, verify the installed version of Ansible:
ansible –version
For Ubuntu
Step 1: Ensure APT Package Manager is Updated
Open the terminal and run the following command to update the package manager:
sudo apt update
Step 2: Install Ansible
Install Ansible using the apt package manager:
sudo apt install ansible
Step 3: Verify the Installation
Verify the installation by checking the Ansible version:
ansible –version
For Windows (via WSL)
Step 1: Install Windows Subsystem for Linux (WSL)
Ansible runs on Linux, so use Windows Subsystem for Linux (WSL) to run it. Open PowerShell as Administrator and run:
wsl –install
After the installation is complete, restart your computer and open the Ubuntu terminal from the Start menu.
Step 2: Install Ansible Using APT (within WSL)
Inside the Ubuntu terminal, update the package manager and install Ansible:
sudo apt update
sudo apt install ansible
Step 3: Verify the Installation
Verify the installation by running:
ansible –version
Why is Ansible called Agentless ?
Ansible is referred to as agentless because it does not require installing any additional software or agents on the remote servers to manage them. Let’s understand this concept with an example:
Imagine you need to install a library or package on a remote server. Without Ansible, you would manually log in to the server via SSH, run commands step by step, and repeat this process for each server. This approach is tedious and time-consuming, especially when managing multiple servers.
With Ansible, you only need to create a project, define the tasks (such as installing a library) in a playbook, and specify the target servers. By running a single Ansible command, you can execute these tasks simultaneously across multiple servers, streamlining the process. This is made possible because Ansible communicates directly over SSH (or WinRM for Windows) without requiring any additional agents on the managed nodes. This simplicity and efficiency are why Ansible is called agentless.
How does’t it works :
For writing an ansible playbook you have to follow the yml extension code snippets .
What is YML ?
YAML stands for “Yet another Markup Language”, indicating its evolution beyond being just a markup language. YAML is a human-readable data serialization language often used for configuration files and data exchange between programs. It is widely adopted in various domains because of its simplicity and readability.
Example of file : vm-setup-playbook.yml
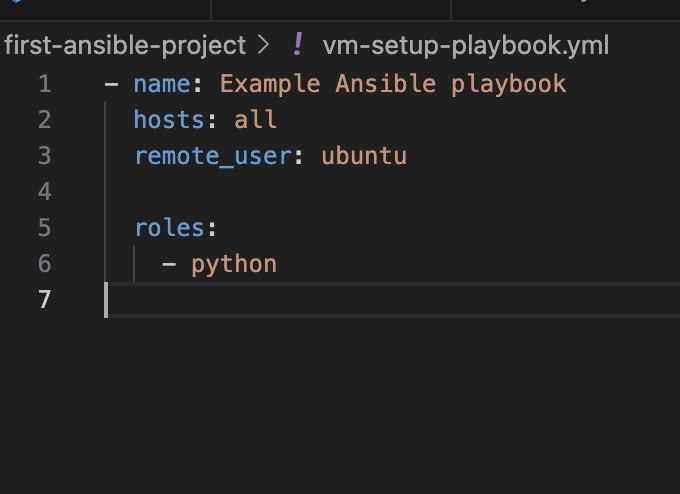
How to write a YML file :
At the time of writing YML you have to follow these steps
Start with —
- The first line of a YAML file should typically start with three dashes (—).
- This signifies the beginning of a YAML document.
Use Proper Indentation
- YAML relies on spaces for structure (not tabs).
- Indentation should be consistent throughout the file. Use 2 or 4 spaces per level.
Define Tasks or Objects Using Keys and Values
- Keys and values are separated by a colon (:).
- Ensure there is a space after the colon for readability.
Use a Dash (-) for Lists
- Lists are defined using dashes (-), followed by a space.
Indent Sub-Keys Under Parent Keys
- For hierarchical data, use proper indentation (e.g., sub-keys under parent keys).
Add Comments
- Use the # symbol to add comments in YAML.
Avoid Quoting Unless Necessary
- Strings don’t require quotes unless they contain special characters (e.g., : or #).
Use Double Dash (–) Before Task Names (Optional)
- For additional clarity, you can use — before defining a task or block.
Ansible Project Folder Structure with Explanation :
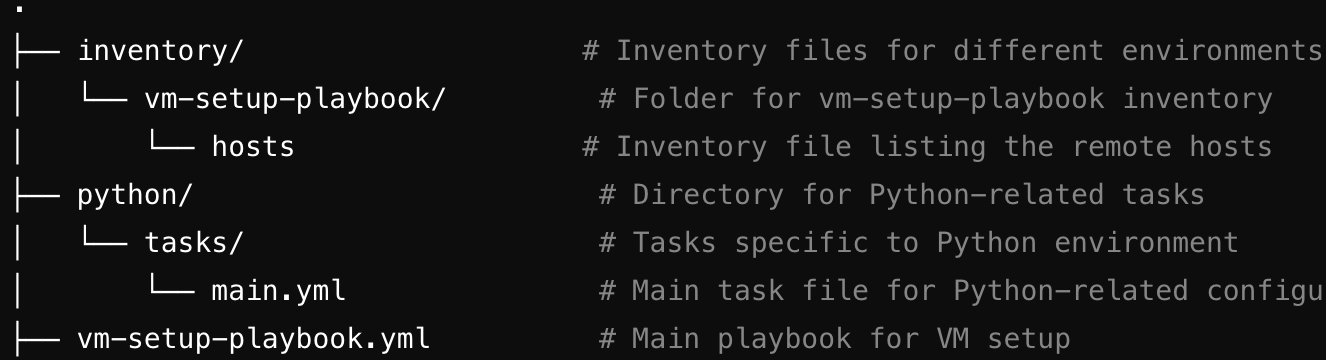
- inventory/
This directory contains the inventory files for your different environments, in your case specifically for vm-setup-playbook.
inventory/vm-setup-playbook/hosts
This file defines the remote hosts that Ansible will manage. It can also specify groups of hosts (e.g., webservers, dbservers), and any host-specific variables. This is the Ansible inventory file, listing all your servers.

python/
This directory contains tasks related to Python configurations, ensuring your Python environment is correctly set up on your remote servers.
- python/tasks/main.yml
This is the main task file that Ansible will use for installing and configuring Python on the remote hosts. This could include tasks like installing Python, setting up virtual environments, and installing required Python packages.

vm-setup-playbook.yml
This is the main Ansible playbook file that includes tasks for setting up your virtual machine. It can reference multiple roles, inventories, and tasks, and execute them on the appropriate hosts.
Example vm-setup-playbook.yml:
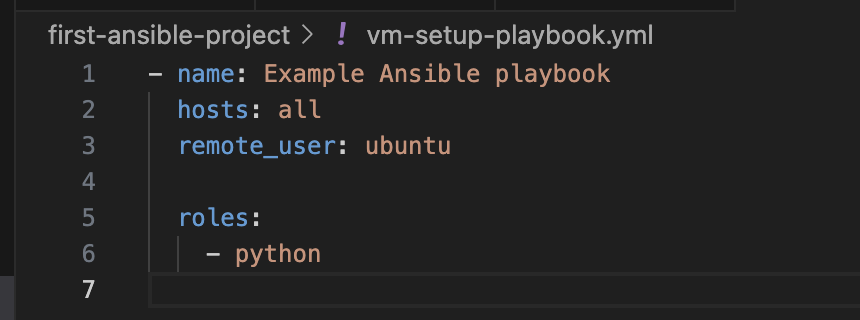
How to use a multi server using ansible ?
To use multiple servers with Ansible and manage them using a single hosts file, you can define groups and execute tasks based on specific conditions or sequences. For example, if you have two servers managing an application and want to update one server while ensuring the other remains active, you can achieve this with Ansible playbooks and inventory management.
1. Create an Inventory File (hosts file)
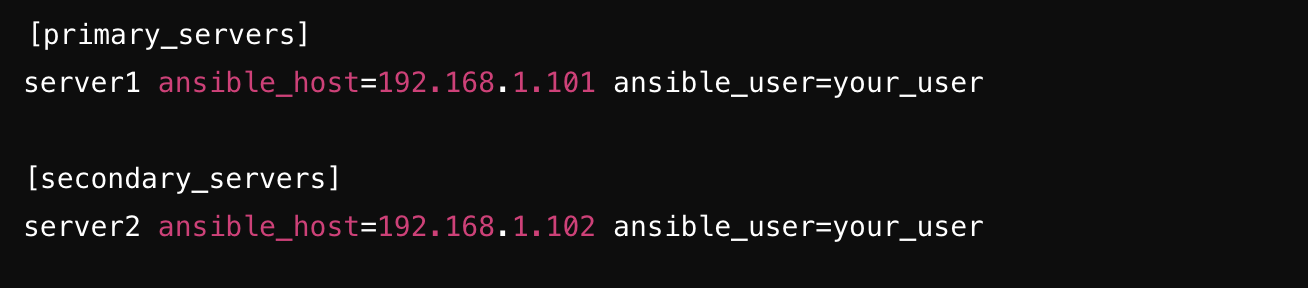
As you can see in the host file we have two server ip addresses and you want to execute your ansible playbook on both servers then in root level yml in hosts variable just add the value all and run your ansible code. After running the .yml playbook will execute on both servers.
How to execute for one server ?
In the ansible there are two ways to execute the yml on specified servers .
Executing an Ansible Playbook on Specified Servers: Method 1
In this approach, you can modify the hosts value in the root-level YAML file to specify the desired group.
For example, if your playbook targets two server IP addresses, update the hosts value in the playbook with the appropriate group name before execution.
What is the group name?
As shown in the host file, two groups are defined:
- primary_servers
- secondary_servers
These are the group names you can use in the hosts field.
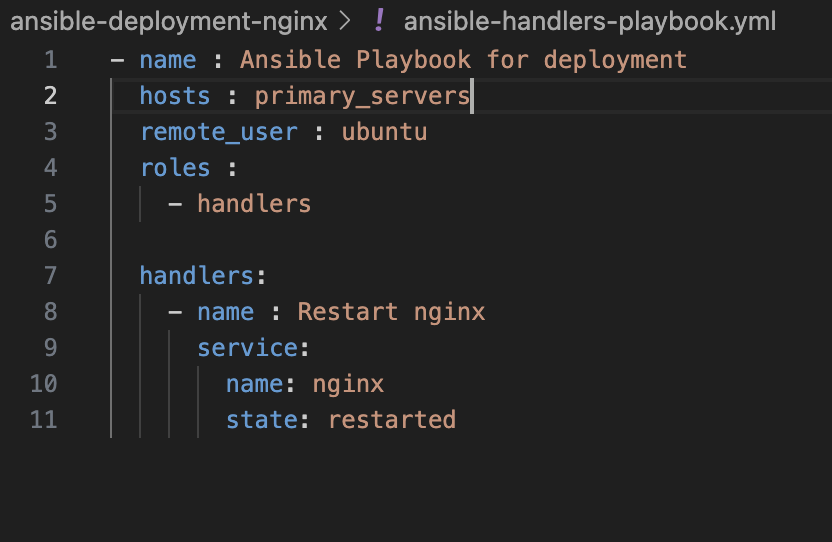
In the root-level YAML file of the playbook, the hosts value is set to primary_servers. This means that when you run the Ansible playbook, it will target the servers listed under the primary_servers group in the inventory file.
For instance, if your inventory file contains server details organized into groups like primary_servers and secondary_servers, setting hosts: primary_servers in the playbook ensures that the tasks defined in the playbook will only be executed on the servers belonging to the primary_servers group.
To execute the playbook, use the appropriate Ansible command, and the playbook will automatically focus on the specified group (primary_servers) as defined in the hosts field.
Executing an Ansible Playbook on Specified Servers: Method 2
This method is straightforward and requires no changes to the playbook file. If you want to execute Ansible commands on a specific group of servers, you can specify the group directly in the command line without modifying the playbook’s hosts field.
To do this, use the –limit option in the Ansible command. For example:
ansible-playbook –inventory inventory/blw-playbook/hosts –limit <host-or-group> blw-playbook.yml
Here’s how it works:
The hosts flag specifies the inventory file that contains the server groups and their IP addresses.
- The update_app.yml is the playbook you want to execute.
- The –limit primary_servers flag ensures that the playbook is executed only on the servers listed under the primary_servers group in the inventory.
- This approach provides flexibility, allowing you to run the playbook on different groups or subsets of servers without altering the playbook itself. Simply adjust the group name in the command (primary_servers, secondary_servers, etc.) as needed.
Why Do We Need Error Handling in Ansible?
Error handling in Ansible is essential to ensure that playbooks can handle unexpected issues gracefully without halting the execution unnecessarily. Let’s consider a scenario to understand this better:
Scenario: Updating Builds on Two Servers
You have two servers where you want to update a build. Before uploading the new build, it is mandatory to delete the old build from the servers. The playbook is written to perform the following steps:
- Delete the old build from both servers.
- Upload the new build to both servers.
Now, imagine this situation:
- The playbook starts by deleting the old build from the servers, and this step is successful.
- Next, when it tries to upload the new build, the first server is down, but the second server is operational.
Since the first server is down, an error will occur during the upload step. By default, this will stop the playbook execution entirely, and the build update will not proceed for the second server either, even though it is functioning.
To handle such scenarios, error handling ensures that the failure on one server does not prevent the playbook from completing tasks on other servers.
How to Handle Errors in This Case
ignore_errors: true
Use this directive to allow the playbook to continue execution even if a task fails. For example:
yaml
Copy code
– name: Upload new build to the server
copy:
src: /path/to/build
dest: /path/to/destination
ignore_errors: true
- Effect:
If the task to upload the build on the first server fails, Ansible will log the error but continue uploading the build to the second server.
Custom Error Handling with any_errors_fatal: false
The any_errors_fatal directive ensures that errors on one server do not stop execution for other servers in the playbook. For example:
yaml
– hosts: all
any_errors_fatal: false
tasks:
– name: Delete old build
file:
path: /path/to/old/build
state: absent
– name: Upload new build
copy:
src: /path/to/new/build
dest: /path/to/destinationEffect:
If an error occurs on one server (e.g., the first server is down), the playbook continues to execute tasks for the remaining servers.

Rishabh Mishra
Software Developer



{kind=link}
{kind=link}
{kind=link}